

Ever since software engineering became a profession, we have been trying to serve users all around the globe. With this comes the issue of scaling and how to solve it. Many times these thoughts of scaling up our software to unimaginable extents are premature and unnecessary.
This has turned into something else altogether with the rise of serverless architectures and back-end-as-a-service providers. Now we’re not facing issues of how to scale up and out, but rather how to scale our database connections without creating heavy loads.
With the reduced insight we have about the underlying infrastructure, there’s not much we can do except for writing sturdy, efficient code and use appropriate tools to mitigate this issue.
Or is it? 🤔
How do databases work with serverless?
With a traditional server, your app will connect to the database on startup. Quite logical, right? The first thing it does is hook up to the database via a connection string and not until that’s done, the rest of the app will initialize.
Serverless handles this a bit differently. The code will actually run for the first time only once you trigger a function. Meaning you have to both initialize the database connection and interact with the database during the same function call.
Going through this process every time a function runs would be incredibly inefficient and time-consuming. This is why serverless developers utilize a technique called connection pooling to only create the database connection on the first function call and re-use it for every consecutive call. Now you’re wondering how this is even possible?
The short answer is that a lambda function is, in all essence, a tiny container. It’s created and kept warm for an extended period of time, even though it is not running all the time. Only after it has been inactive for over 15 minutes will it be terminated.
This gives us a time frame of 15 to 20 minutes where our database connection is active and ready to be used without suffering any performance loss.
Using Lambda with MongoDB Atlas
Here’s a simple code snippet for you to check out.
https://medium.com/media/5efdddb491b4180b9d658dc575c9cb63/href
Once you take a better look at the code above you can see it makes sense. At the top, we’re requiring mongoose and initializing an object called connection. There’s nothing more to it. We’ll use the connection object as a cache to store whether the database connection exists or not.
The first time the db.js file is required and invoked it will connect mongoose to the database connection string. Every consecutive call will re-use the existing connection.
Here’s what it looks like in the handler which represents our lambda function.
https://medium.com/media/dad768c8d9c928edc9fc7e3cb3320633/href
This simple pattern will make your lambda functions cache the database connection and speed them up significantly. Pretty cool huh? 😊
All of this is amazing, but what if we hit the cap of connections our database can handle? Well, great question! Here’s a viable answer.
What about connection limits?
If capping your connection limit has you worried, then you might think about using a back-end-as-a-service to solve this issue. It would ideally create a pool of connections your functions would use without having to worry about hitting the ceiling. Implementing this would mean the provider will give you a REST API which handles the actual database interaction while you only use the APIs.
You hardcore readers will think about creating an API yourselves to house the connection pool or use something like GraphQL. Both of those solutions are great for whichever use case fits you best. But, I’ll focus on using off-the-shelf tools for getting up and running rather quickly.
Using Lambda with MongoDB Stitch
If you’re a sucker for MongoDB, like I am, you may want to check out their back-end-as-a-service solution called Stitch. It gives you a simple API to interact with the MongoDB driver. You just need to create a Stitch app, connect it to your already running Atlas cluster and your set. In the Stitch app, you make sure to enable anonymous login and create your database name and collection.
Install the stitch npm module and reference your Stitch app id in your code then start hitting the APIs.
https://medium.com/media/9b18d2bcb58b9bf534053b2239b36666/href
As you can see the pattern is very similar. We create a Stitch client connection and just re-use it for every consequent request.
The lambda function itself looks almost the same as the example above.
https://medium.com/media/f3b7dfdfdde76e78d41c1a25843a9323/href
Seems rather similar. I could get used to it. However, Stitch has some cool features out of the box like authentication and authorization for your client connections. This makes it really easy to secure your routes.
How to know it works?
To make sure I know which connection is being used at every given time, I use Dashbird’s invocation view to check my Lambda logs.
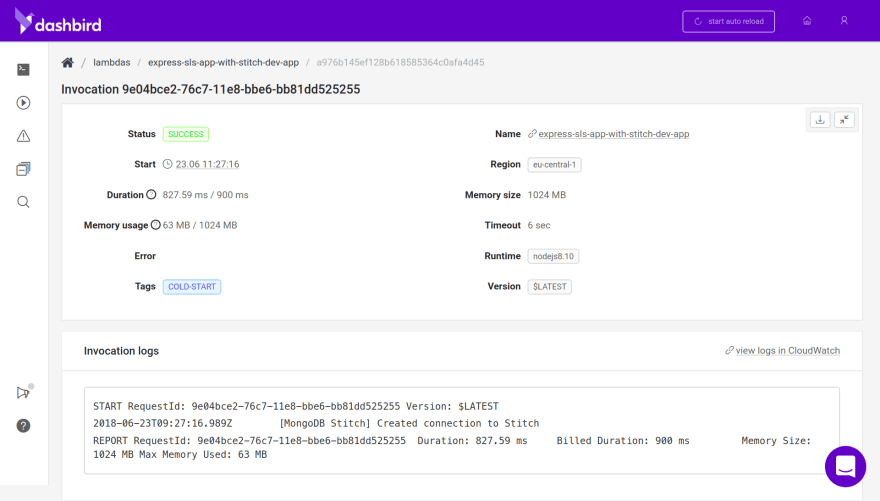
Here you can see it’s creating a new connection on the first invocation while re-using it on consecutive calls.
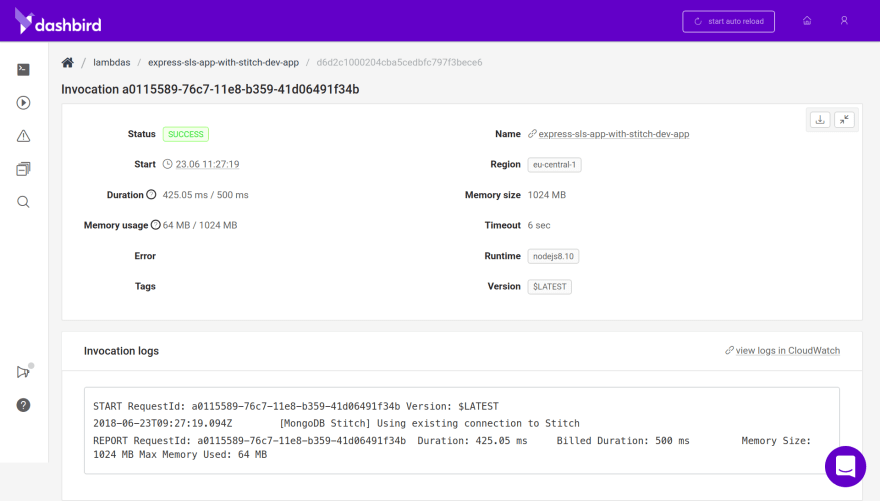
The service is free for 14 days, so you can check it out if you want. Let me know if you want an extended trial or just join my newsletter. 😊
Wrapping up
In an ideal serverless world, we don’t need to worry about capping our database connection limit. However, the amount of users required to hit your APIs to reach this scaling issue is huge. This example above shows how you can mitigate the issue by using back-end-as-a-service providers. Even though Stitch is not yet mature, it is made by MongoDB, which is an amazing database. And using it with AWS Lambda is just astonishingly quick.
To check out a few projects which use both of these connection patterns shown above jump over here:
- Building a Serverless REST API with MongoDB
- Building a Serverless REST API with Stitch
If you want to read some of my previous serverless musings head over to my profile or join my newsletter!
https://medium.com/media/a80131fe3b67db34ff64d435f0cc9039/href
Or, take a look at a few of my other articles regarding serverless:
- How to deploy a Node.js application to AWS Lambda using Serverless
- Getting started with AWS Lambda and Node.js
- A crash course on securing Serverless APIs with JSON web tokens
- Migrating your Node.js REST API to Serverless
- Building a Serverless REST API with Node.js and MongoDB
- A crash course on Serverless with Node.js
Hope you guys and girls enjoyed reading this as much as I enjoyed writing it. Hit that tiny heart for others to see this here on Medium. Until next time, be curious and have fun.
Originally published at dev.to.
Solving invisible scaling issues with Serverless and MongoDB was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.

