

There come times in a programmer’s career when they realize that their code simply needs to run faster. Whether it’s creating low-latency APIs or programs that parse through billions of data points, speed is a huge factor.
What can you do when your code simply runs too slow?
Luckily, there are many tools in the programming tool belt to make code run faster. The first thought that may come to your mind is caching. But what about when caching isn’t an option?
Another viable choice is multithreading. In order to talk about multithreading, it’s important to discuss what processes and threads are. In the simplest term, you can think of a process as an executing program.
For example, run ps aux in a terminal to see all the processes currently running on your computer. All of those processes correspond to a program or application. The web browser that you are reading this on is using one or more processes.

You can think of a thread as a worker for the process. If the process is the boss, then the threads are the faithful employees. Each process initiates a single thread but can create more if needed.
All threads that are within one process share the same heap memory but contain their own execution stacks. This means threads can share data but not function calls.
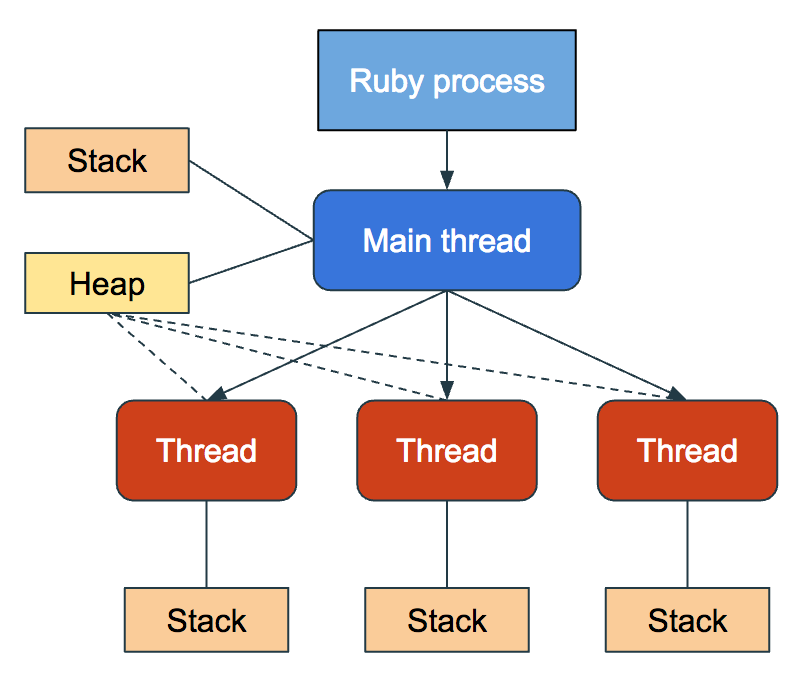
The reason why multithreading is useful is that an executing program can delegate tasks to many different threads. It would be equivalent to an employer hiring fifty programmers to build an entire SaaS product instead of just one. The best way to show this is with an example.
As a note, all of the code examples in this post will be written in Ruby and will use the Thread class to spin up new threads.
Let’s say that you have a program that needs to loop through a list of tasks and complete them. In this example, let’s say that each task takes about 1 second to execute. If you relied on a single thread to perform this loop, it would take 10 seconds to complete.
https://medium.com/media/d709f6b4d2eb91b68dc8aac0e4174722/href
$ ruby 01_serial_loop.rb
1
2
3
4
5
6
7
8
9
10
10.02504587173462 seconds to complete.
However, if we were to give each individual task to a different worker, it would only take 1 second as all of the workers would be working concurrently. In Ruby, this is as simple as creating a new instance of Thread.new and passing it a block to execute. Each Thread.new returns a new instance of a thread.
However, it’s not enough to just spin up new threads. The program has to make sure those threads finish before exiting. If a program doesn’t explicitly wait for the threads to finish, the program will exit too early.
In Ruby, the join method has to be called on each thread instance so that each thread joins back with the main thread.
https://medium.com/media/19cf57385b6a539d601830c46cd439c9/href
$ ruby 02_multithread_loop.rb
5
4
8
6
10
2
1
9
3
7
1.0051839351654053 seconds to complete.
Concurrency and Parallelism
One thing you may have noticed from the concurrency example is that the threads returned in a random order. Threads don’t finish in the same order that they were initiated. They are asynchronous. This is the main concept behind concurrency and parallelism. Each thread initiates and finishes at its own pace without regard for the other threads.
While concurrency and parallelism aren’t the same, they are similar. The difference between each concept is outside the scope of this article but can be read about here.
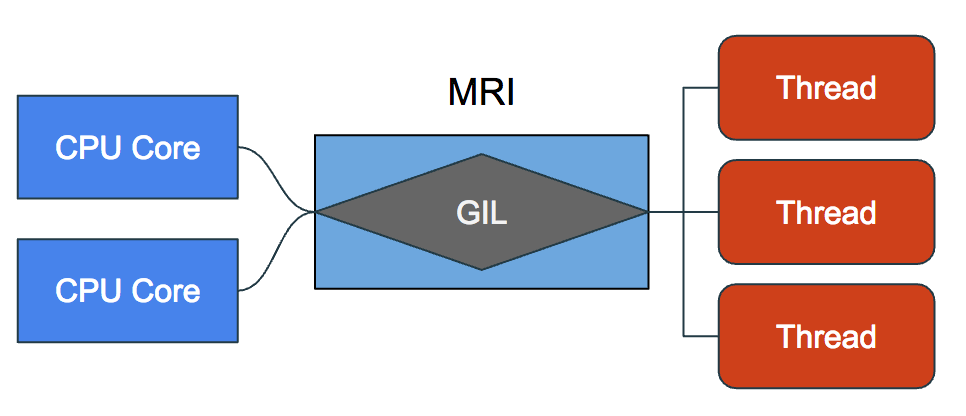
One important thing to note is that due to Ruby language constraints — notably the Matz Ruby Interpreter(MRI) and Global Interpreter Lock(GIL) — the standard version of Ruby is incapable of true parallelism. However, it can do concurrency just fine.
Race Conditions
Concurrency is important to understand as it can lead to hard-to-fix bugs if you aren’t careful. One such bug that can arise from multithreading is known as a race condition.
The most common form of a race condition is when multiple threads try to access the same piece of memory at the same time. The problem with this scenario is that many operations can be ignored, or worse, the memory could get corrupted.
Let’s look at an example where many threads are trying to increment a global counter. We start off the counter at 0 and create 1000 threads, all with the task of incrementing the counter by one.
https://medium.com/media/815de821903acadff55f5c05f904731e/href
If all goes well, the counter should end up at 1000. But remember, each individual thread is operating on a single variable or piece of memory. With so many different operations occurring on a single piece of state, data corruption can occur. Let’s see what happens in this scenario.
$ ruby 03_global_counter.rb
count = 1000
Voila! It worked! But why? So many operations occurring on a single piece of state will surely corrupt it, right? Not always.
In this case, the operation that each thread had to execute was so fast that by the time the next thread was created, the first thread had finished. There simply wasn’t enough time for multiple threads to overwrite each other.
But what if that wasn’t the case? What if each thread had to do some work, such as an API call, before operating on a piece of state? We can simulate that extra work by having each thread sleep for a random amount of time before incrementing the counter. This will prevent the threads from finishing instantaneously.
https://medium.com/media/5f390dd8f719785dd8321d85b118f9ad/href
$ ruby 04_sleeping_threads.rb
count = 1000
“Hm,” you may be thinking. “Looks like it still worked. I don’t think this guy knows what he’s talking about.”
Don’t get too comfortable. The reason why this example worked is that the standard Ruby runtime isn’t capable of parallelism. By default, threads will only execute one at a time on a global variable. With the standard Ruby runtime, you don’t have to worry too much about race conditions.
But what if you weren’t using the standard Ruby runtime? What if you were using a different language or runtime, like JRuby, that is capable of parallelism? If we switch our Ruby version to JRuby, we can see the result of race conditions.
# Change ruby version to JRuby
$ rbenv local jruby-9.1.10.0
$ ruby 04_sleeping_threads.rb
count = 864
Yikes. Looks like we’re missing 136 counts from our counter. That means that at one or more points, multiple threads overwrote each other.
Since JRuby runs on the Java Virtual Machine and is capable of parallelism, our program is vulnerable to race conditions. In terms of thread safety, it is very unsafe.
Multiple Global Variables
This vulnerability is even more pronounced if we access multiple pieces of shared data in our threads. In the following program, I have two counters that increment and the difference between the counters are calculated.
https://medium.com/media/7d962d2566119a5deb490522aa0b17f1/href
If all goes well, we should see that both of the final counts should be at 1000 and the diff should equal 0, meaning that the count values never became out of sync at any point.
$ ruby 05_multiple_counters.rb
count1 : 1000
count2 : 1000
diff : 0
The time it took to execute both increments and calculating the difference is simply too fast for multiple threads to overlap each other. As you might imagine, if we add in additional computational randomness and enable parallelism, that isn’t the case.
https://medium.com/media/e805931f379a0a369e7cfc909f51696a/href
$ rbenv local jruby-9.1.10.0
$ ruby 06_mulitple_values_sleep.rb
count1 : 890
count2 : 869
diff : 253904
What’s interesting, however, is that even the normal Ruby runtime can get tripped up in this scenario.
$ rbenv local 2.4.1
$ ruby 06_mulitple_values_sleep.rb
count1 : 1000
count2 : 1000
diff : 339498
While only one thread can access a counter at a time and both counts end up at the expected 1000 count value, they weren’t always in sync. While one thread was incrementing count2, another thread was incrementing count1 causing the values to differ. This difference was captured in the diff. While the standard Ruby MRI prevents a lot of typical race conditions, it’s not immune to them.
Preventing Race Conditions
For those of you unfamiliar with race conditions, you may wonder how to prevent them. “There has to be a way of making our programs deterministic and thread-safe, right?” you may ask. Fortunately, there is. We can use something called a Mutual Exclusion Object. Mutex, for short.
A mutex will ensure that only one thread can access a piece of memory at a time. Using a mutex in Ruby is very easy. All you need to do is create a new instance of the Mutex class and wrap the vulnerable code in a synchronize block.
https://medium.com/media/38ae7851fd37039099caf55db8c73771/href
$ ruby 07_thread_safe.rb
count1 : 1000
count2 : 1000
diff : 0
Multithreading isn’t always the best solution
The trade-off of using a mutex is that your program will run slower than without it due to threads having to wait. While a longer running program is better than an inaccurate program, using a mutex may defeat the purpose of multithreading. The program may be better off running serially.
For example, if we take the last example, reduce the thread count to 100, and time how long it takes to run, you can see that there is minimal difference between multithreading and non-multithreading. In fact, multithreading can be slower due to the overhead of creating the threads and context switching between them.
https://medium.com/media/59b8c26579256fd070b948c38916524e/hrefhttps://medium.com/media/eb02c2a98c36131769c2630b4a40aae0/href
# Non-Multithreading Result
$ ruby 08_single_thread_multiple_counter.rb
count1 : 100
count2 : 100
diff : 0
96 seconds to finish
# Multithreading Result
$ ruby 09_multi_thread_mutex.rb
count1 : 100
count2 : 100
diff : 0
99 seconds to finish
The multithreaded program performed worse due to the overhead of creating 100 threads and forcing them all to wait with the mutex. Programs that rely heavily on accessing global variables may not benefit from multithreading.
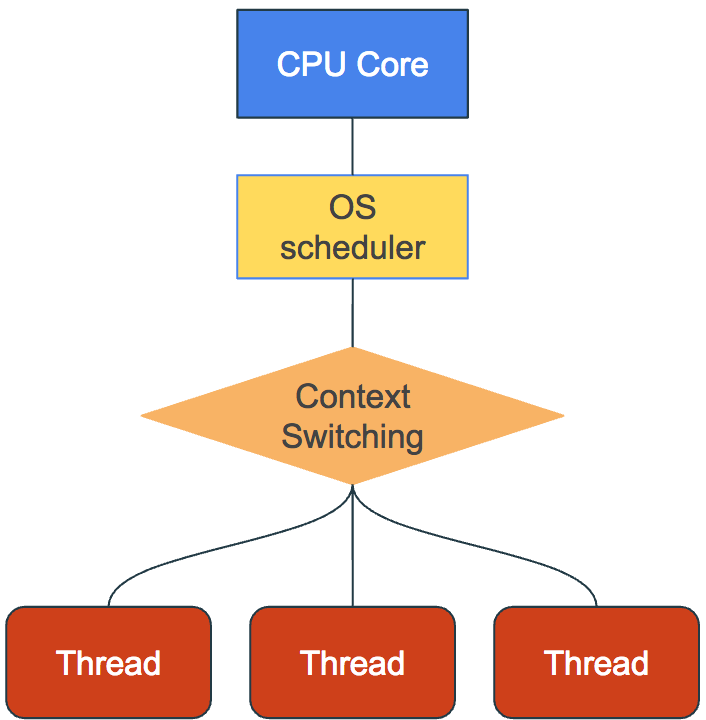
Also, tasks that must be executed in a specific order would not be suited for multithreading. As we saw earlier in this article, threads do not finish in a deterministic order.
An Ideal Use Case
While multithreading may not be appropriate for every situation, there are many where it’s perfect. One example is when your program has to make multiple requests to fetch data, whether from an internal service or a third-party.
Imagine you were creating an API endpoint that returned data about a user’s account. In the response is data that your company neither owns nor manages, such as GitHub Repos. To get a user’s GitHub information, the program will need to issue many requests to GitHub.
The requirements of this API are that the data must be accurate and the latency has to be less than a second. The faster, the better.
In the following example API, the program pulls all the repo names from a file (to simulate a request to a database). The program then loops over each repo name and makes a request to the GitHub API to retrieve more data about it.
https://medium.com/media/28e37dee5a50358829d3def4e11d4537/href
As you might imagine, this can lead to long response times for the user.
$ curl localhost:4567/slow_response
{
“response”: [
…
],
“time”: 7.479549884796143
}In this example, it takes more than 7 seconds for retrieve the user’s data. This isn’t acceptable. We need to get this to under a second so that it can scale and provide a better user experience.
One possible way of shortening this response time is by caching all the repo data in a database. The problem with this solution is that repo data changes often. The title, number of watchers, number of stars, and forks. These values are all subject to change, which would make the results inaccurate. Incorrect results aren’t allowable.
Another tool to consider is multithreading. Instead of making API requests to GitHub one at a time, a separate thread could be spun up for each request.
https://medium.com/media/fad8afbcc8fa8a6678f3483b28a043a4/href
$ curl localhost:4567/fast_response
{
“response”: [
…
],
“time”:0.5799121856689453
}By only changing and updating 3 lines, the response time dropped from over 7 seconds to under a second. It’s possible to make this code even more performant by enabling parallelism.
$ rbenv local jruby-9.1.10.0
$ ruby sinatra_demo_fast_response.rb
[2018–09–29 11:47:21] INFO WEBrick 1.3.1
[2018–09–29 11:47:21] INFO ruby 2.3.3 (2017–05–25) [java]
== Sinatra (v1.4.8) has taken the stage on 4567 for development with backup from WEBrick
# In a new terminal tab
$ curl localhost:4567/fast_response
{
“response”: [
…
],
“time”:0.3163459300994873
}With parallelism in place, the response time can be cut to a third of a second. Our users would be quite happy with that performance.
I hope that you gleamed some new insights about multithreading. Concurrency is a language agnostic tool that’s excellent for optimizing your code. Most languages support multithreading or multiprocessing in some fashion.
If you found this article to be beneficial or insightful, please leaves some 👏. And the next time you find yourself needing to create a fast program, I hope you consider multithreading as a possible solution.

Need faster code? Try Multithreading was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
