

Handling large images has always been a pain in my side since I started writing code. Lately, it has started to have a huge impact on page speed and SEO ranking. If your website has poorly optimized images it won’t score well on Google Lighthouse. If it doesn’t score well, it won’t be on the first page of Google. That sucks.

TL;DR
I’ve built and open-sourced a snippet of code that automates the process of creating and deploying an image resize function and an S3 bucket with one simple command. Check out the code here.
But if you want to follow along and learn how to do it yourself, keep reading.
Where do we start?
Luckily enough, there is a way to solve the issue of bad image optimization with little to no hassle. Today we’ll build an AWS Lambda function to resize images on-the-fly.
The images will be stored in an S3 bucket and, once requested, will be served from it. If you need a resized version, you’ll request the image and supply the height and width. This will trigger a function. It’ll grab the existing image, resize it, return it back to the bucket and then serve it from the bucket.
This scenario will only resize an image for a given set of dimensions once. Every subsequent request to the image of that size will be served from the bucket. Pretty cool huh? Here’s a diagram, because who doesn’t love diagrams.
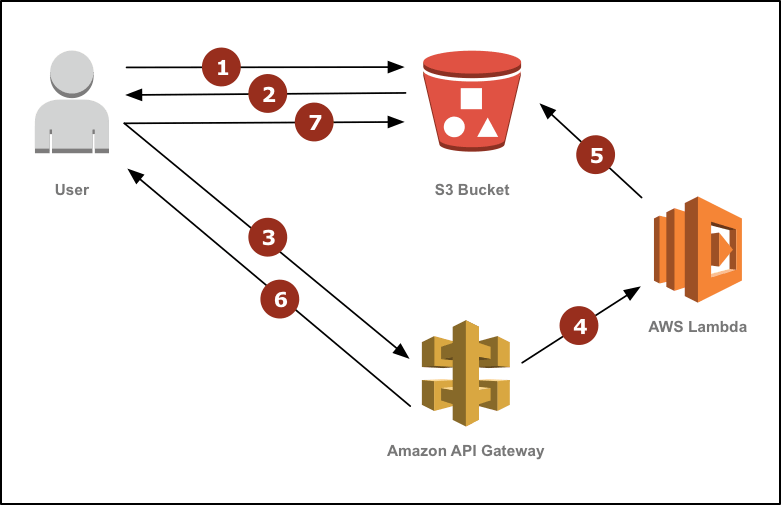
Because I already assume you know how to use the Serverless Framework and have already been introduced to the basics of serverless, Docker and AWS, I’ll immediately jump into the gist of things. Here’s an overview of what we’ll be doing.
- Create the project structure
- Create a secrets file
- Write the AWS Lambda function configuration
- Write AWS Lambda function source code
- Write S3 Bucket configuration
- Deploy with Docker
- Test with Dashbird
Note: Please install Docker and Docker Compose before continuing with this tutorial.
The funny thing here is that we need to use Docker to deploy this service because of Sharp. This image-resize module has binaries that need to be built on the same operating system as it will run on. Because AWS Lambda is running on Amazon Linux, we need to npm install the packages on an Amazon Linux instance before running sls deploy.
With that all out of the way let’s build some stuff.
Create the project structure
The best way of explaining this complex structure will be with an image.
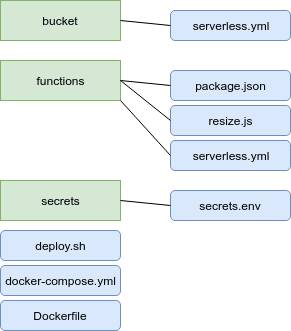
Folders in green and files in blue. Check out the repo for further insight.
Create a secrets file
We’ll create a secrets.env file in the secrets folder to hold our secrets and inject them into our Docker container once it spins up.
SLS_KEY=XXX # replace with your IAM User key
SLS_SECRET=YYY # replace with your IAM User secret
STAGE=dev
REGION=us-east-1
BUCKET=images.yourdomain.com
Note: The deploy.sh script will create a secondary secrets.json file only to hold the domain name of our API Gateway endpoint.
Write the AWS Lambda function configuration
Open up the functions folder, and start by creating the package.json file. Paste this in.
https://medium.com/media/a97cc5de4c04a6d0c3d00c802f1a5455/href
No need to run any install, because we need to run the Docker container first. Note that we’re adding a tracing plugin to enable X-Ray because it’s awesome.
Moving on, let’s create the serverless.yml file to configure our function.
https://medium.com/media/6e2f68ec605494cb374818048b20f143/href
As you can see we’re grabbing a bunch of values from the env and also allowing the function to access the BUCKET we specified and some X-Ray telemetry.
Write AWS Lambda function source code
Only the code left now. Here’s what we’ll do. Because images can get quite large and we don’t want to risk loading several megabytes into the lambda function’s memory, I’ll show you how to use Node.js streams to read the image from an S3 stream, pipe it to Sharp, and then write it back to S3, once again, as a stream.
Ready? Let’s do it in two steps. First, define the helper functions we need in order to create the streams, then create the handler function itself which our lambda will invoke.
https://medium.com/media/a7e315972fab5b88a8543a93c3fe76eb/href
Here we’re defining constants and the constructor functions for our streams. What’s important to note is that S3 doesn’t have a default method for writing to storage with a stream. So you need to create one. It’s doable with the stream.PassThrough() helper. The abstraction above will write the data with a stream and resolve a promise once it’s done.
Moving on, let’s check out the handler. Just underneath the code above, paste this in.
https://medium.com/media/60046db2fdf3d9a8985be2c36003898d/href
The query string parameters will look like this /1280×720/image.jpg. Which means we grab the image dimensions from the parameters by using a regex match. The newKey value is set to the dimensions followed by a / and the original name of the image. This will create a new folder named 1280×720 with the image image.jpg in it. Pretty cool.
Once we trigger the streams and await the promise to resolve we can log out the data and return a 301 redirect to the location of the image in the bucket. Note that we will enable static website hosting on our bucket in the next paragraph.
Write S3 Bucket configuration
The bucket configuration will mostly consist of default CloudFormation templates, so if you’re a bit rusty, I’d advise you brush up a bit. But, the gist of it is simple enough to understand. Open up the bucket folder and create a serverless.yml file.
https://medium.com/media/dddca8e8831afafdb4193e0badb42bcc/href
Once we enable the static website hosting option on our bucket, it will behave like any website. This lets us serve images from it and utilize the 404 error redirect rule.
If no image is found, the bucket will trigger the 404, which redirects to our lambda function. Then resize the original image to the requested dimensions, and put it back to the bucket at the exact route it was requested from.
Just like magic!
Deploy with Docker
Here comes the fun part! We’ll create a Dockerfile and docker-compose.yml file to create our Amazon Linux container and load it with .env values. That’s easy. The hard part will be writing the bash script to run all commands and deploy our function and bucket.
Starting with the Dockerfile, here’s what you need to add.
https://medium.com/media/5b3a48ae4fdd6b43f5849ece02041eb9/href
Because Amazon Linux is rather basic, we need to install both gcc and Node.js at the get-go. Then it’s as simple as any Dockerfile you’ve seen. Install the Serverless Framework globally, copy over the source code, install the npm modules in the functions directory and run the deploy.sh script.
The docker-compose.yml file is literally only used to load the .env values.
https://medium.com/media/a36be8822adeeed46f909fb000b780b6/href
That’s it. The Docker part is done. Let’s write some bash.
Starting out simple, we’ll define the initial variables, configure our serverless installation and deploy our function.
https://medium.com/media/d363d78aeb4cdc90d0e0e1f9480deb6b/href
Once we have deployed it, we need to grab the domain name of our API Gateway endpoint and put it in a secrets.json file which will be loaded into our serverless.yml file from the bucket directory. To do this I just did some regex magic. Add this at the bottom of your deploy.sh.
https://medium.com/media/118456674b2d935233625e4135c8645e/href
Now you have a secrets.json file in the secrets directory. All that’s left is to run the bucket deployment. Paste this final snippet at the bottom of the deploy.sh script.
https://medium.com/media/7021bc4fb8bd1193f20c3da3aae84c2d/href
There we have it! The coding part is done. Would you believe me we only need to run one command now? Open up a terminal window in the root of your project and run:
$ docker-compose up --build
Let it do its magic, and you’ll see everything get created automagically! Please note that the terminal will show you the bucket endpoint which you’ll use to access the images.
Test with Dashbird
The final step is to check if it all works. Let’s upload an image to the bucket, so we have something to resize. Go ahead and find an image you like and want to resize, or just take this one.
It’s rather huge and around 6 MB in size. Here’s the command you want to run to upload it.
$ aws s3 cp --acl public-read IMAGE s3://BUCKET
So, if your bucket name is images and your image name is the-earth.jpg, then it should look like this if you run the command from the directory where the image is located.
$ aws s3 cp --acl public-read the-earth.jpg s3://images
Keep in mind you need to have the AWS CLI installed on your machine, or upload the image through the AWS Console.
Now, try out to request the image through the bucket. Type into your browser the S3 bucket URL.
http://BUCKET.s3-website.REGION.amazonaws.com/the-earth.jpg
You’ll see the original image appear. But, now add dimensions to the URL.
http://BUCKET.s3-website.REGION.amazonaws.com/400x400/the-earth.jpg
This will trigger the resize function and create a 400×400 pixel version of the image. It’ll take a few hundred milliseconds to create and once it’s done, the browser will redirect you to the newly created image. When you try to refresh the URL you’ll see that it’s now fetching the new image, without calling the resize function.
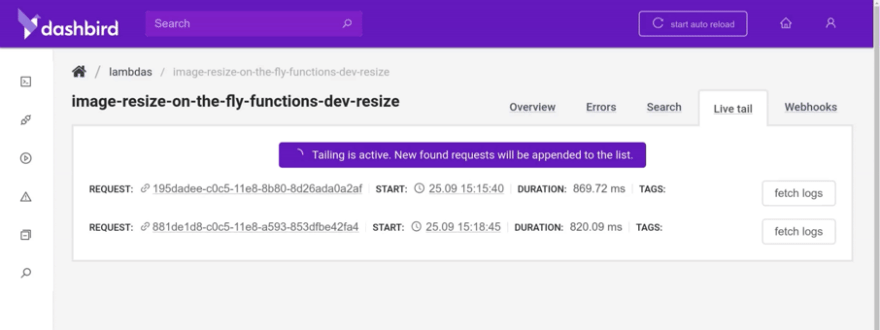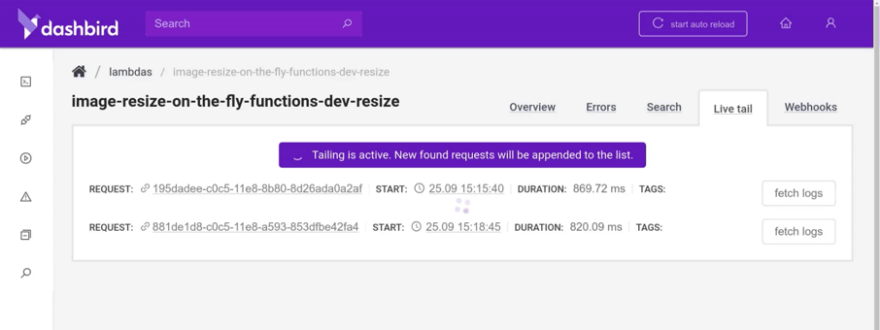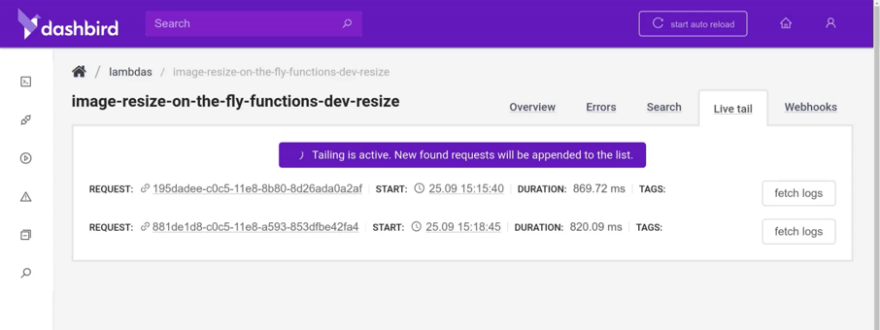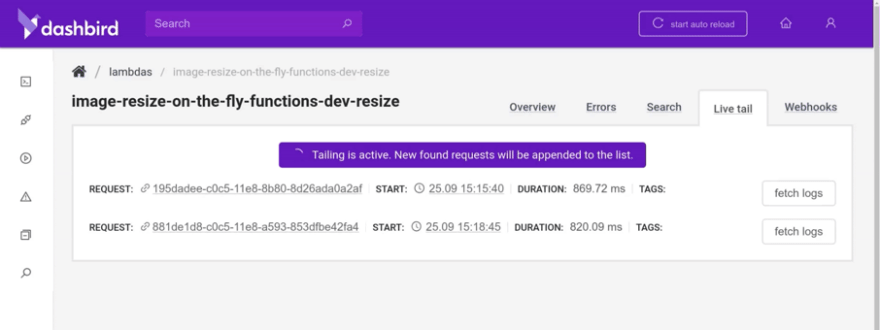
Let’s check the logs in Dashbird and make sure it all works fine under the hood.

Looks fine, but I did make some beginner mistakes when I first tried setting up the function. One of them was forgetting to require a module before using it. Luckily I immediately got an alert that explained what was wrong. Slack alerts are life-savers.

The way I fixed the issue was with the live-tailing feature. It let me check the invocation logs with a few seconds of latency so I could debug the issue. Pretty cool.
Wrapping up
To conclude this little showdev session, I’d like to point out using serverless as a helper to support your existing infrastructure is incredible. It’s language agnostic and easy to use.
We at Dashbird use clusters of containers for our core features that interact heavily with our databases while offloading all the rest to lambda functions, queues, streams and other serverless services on AWS.
And, of course, here’s the repo once again, give it a star if you want more people to see it on GitHub. If you follow along with the instructions there, you’ll be able to have this image resize on-the-fly microservice up and running in no time at all.
If you want to read some of my previous serverless musings head over to my profile or join my serverless newsletter!
https://medium.com/media/a80131fe3b67db34ff64d435f0cc9039/href
I had an absolute blast writing this open-source code snippet. Writing the article wasn’t that bad either! Hope you guys and girls enjoyed reading it as much as I enjoyed writing it. If you liked it, slap that tiny unicorn so more people here on dev.to will see this article. Until next time, be curious and have fun.
Originally published at dev.to.

A crash course on Serverless with AWS — Image resize on-the-fly with Lambda and S3 was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.

